2024-06-03 FineWeb
Date de récolte : 2024-06-03-lundi
🍷 FineWeb: decanting the web for the finest text data at scale
Mon avis :
La taille compte, mais la qualité aussi. C'est, en substance, ce qu'il faut retenir concernant les données d'entraînement des LLM.
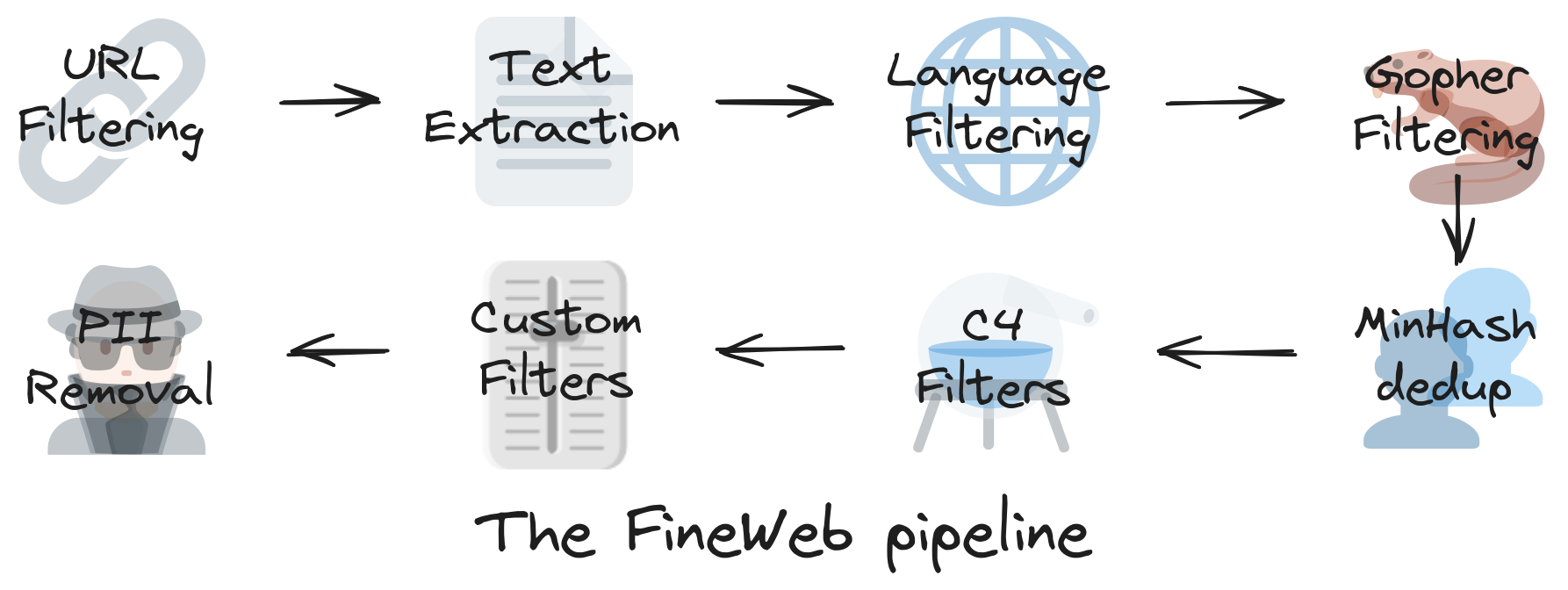
Dans cet article magistral, une équipe de HuggingFace explique comment sélectionner et préparer les données, à une échelle immense (on parle de trillions de mots), pour optimiser l'entraînement des LLM. Le jeu de données qui en résulte, FineWeb, était déjà public depuis quelques temps ; cet article présente aussi un autre jeu de données, FineWeb-Edu, qui est un sous-ensemble de FineWeb centré sur des contenus à haute valeur éducative.
L'article est de très grande qualité, tant sur le plan formel (avec notamment de nombreux graphiques interactifs) que sur le fond. On en retiendra que la notion de texte de qualité, à cette échelle, n'est pas nécessairement intuitive et que le processus de curation des données doit être lui-même fortement data-driven. En fait, de nombreux modèles de machine learning, dont des LLM, sont utilisés tout au long du pipeline de préparation des données pour annoter, classifier, filtrer les données. Au total, ce sont environ 120 000 heures de GPU qui ont été nécessaires pour préparer FineWeb !
De manière plus anecdotique, on notera que d'après les investigations de cette équipe, la présence croissante de données générées par des LLM sur le web ne nuit pas à la qualité de l'entraînement de nouveaux LLM, et il est même possible que ce soit le contraire.